Resuscitare un macchinario industriale afflitto da bit rot
Il bit rot è un fenomeno che affligge, prima o poi, qualsiasi supporto di memorizzazione digitale. È la tendenza che hanno i supporti a degradarsi nel tempo, causando il capovolgimento di alcuni bit, che da zero diventano uno e viceversa.
In base alla posizione e al significato dei bit che degradano possono accadere varie conseguenze: nella migliore delle ipotesi, il difetto riguarda una parte di memoria non utilizzata o che contiene dati non critici. Nella peggiore delle ipotesi, il bitrot colpisce una parte essenziale del sistema che lo manda completamente in tilt.
L’addon di rete
Questo progetto è nato quando l’interfaccia web di un macchinario industriale ha smesso di funzionare, impedendo al proprietario di raccogliere dati e di monitorarne lo stato. Sebbene il display integrato (collegato a un PLC separato) funzionasse ancora, con la parte web ko diventava sensibilmente più difficile da usare.
L’interfaccia web è gestita da un modulo esterno che si collega alla porta seriale del macchinario e agisce da “tramite”. Al suo interno è presente un piccolo computer con Linux che legge e scrive i dati su una scheda SD installata al suo interno.

Prima di mettere le mani sul dispositivo, è importante capire le condizioni correnti. Si è avviato? È bloccato? Cosa sta facendo?
Per capire cosa aspettarci da un modulo funzionante al 100%, possiamo leggere il manuale. Ecco alcune informazioni utili:
- il DHCP non è supportato: l’unico modo per utilizzare il dispositivo è tramite un IP statico
- le credenziali di default sono “guest / guest”
- è presente un’interfaccia web in http sulla porta 80
Ottenere l’accesso
Il dispositivo è stato collegato a un router ed è stato analizzato il traffico di rete. Il mio metodo preferito per ottenere l’accesso a un dispositivo è tramite l’utilizzo dell’indirizzo IPv6 link-local, ma sembra che IPv6 sia stato disabilitato, probabilmente a causa dell’età avanzata del dispositivo o di una configurazione intenzionale.
Non conoscendo l’indirizzo IP statico configurato, dobbiamo connetterci direttamente al dispositivo e tentare ogni singolo IP finchè non riceviamo una risposta, con il programma arp-scan.
$ arp-scan -I enp4s0f4u2 192.168.0.0/24
Interface: enp4s0f4u2, type: EN10MB, MAC: 1c:bf:ce:fb:e3:63, IPv4: 192.168.88.52
Starting arp-scan 1.10.0 with 256 hosts (https://github.com/royhills/arp-scan)
192.168.0.102 00:11:0c:0f:7f:bb Atmark Techno, Inc.
Ora che abbiamo scoperto l’indirizzo IP possiamo riconfigurare la scheda di rete e procedere a una scansione per verificare quali servizi sono ancora attivi.
$ nmap 192.168.0.102
[...]
Host is up (0.00088s latency).
PORT STATE SERVICE
21/tcp open ftp
23/tcp open telnet
Il fatto che FTP e Telnet siano presenti indica che il sistema operativo si è avviato, ma la mancanza di http fa presupporre un problema sul server web. Il server telnet, probabilmente lasciato dagli sviluppatori per comodità, è utile in quanto ci permette di ottenere un accesso diretto alla console del dispositivo.
Prima di tentare un login possiamo connetterci senza credenziali per ottenere ulteriori informazioni sulla dispositivo, leggendo il banner di sistema, che solitamente contiene il nome host e altre informazioni.
$ telnet 192.168.0.102
Trying 192.168.0.102...
Connected to 192.168.0.102.
Escape character is '^]'.
atmark-dist v1.26.1 (AtmarkTechno/Armadillo-440)
Linux 2.6.26-at15 [armv5tejl arch]
WEB-MGR login:
AtmarkTechno è un produttore giapponese di schede embedded, e Armadillo-440 è il nome in codice di una scheda i.MX257 ormai fuori produzione. Fortunatamente, sul loro sito web sono ancora disponibili documentazione e tutto ciò che serve per ripristinare il sistema da zero nel caso fosse necessario.
Il kernel 2.6.26-at15 è stato rilasciato nel 2008, ma consultando l’archivio di Atmark sembra questa versione sia stata utilizzata fino al 2013.
Proviamo ad entrare con le credenziali “guest” presenti sul manuale: nonostante siano relative all’interfaccia web spesso gli sviluppatori, per semplicità, riciclano le password.
WEB-MGR login: guest
Password: *****
[guest@WEB-MGR (ttyp0) ~]$
Successo! Sfortunatamente l’utente guest ha accesso molto limitato alla macchina. Per ottenere un accesso totale è necessario passare all’utente root. Se guest si trova nell’elenco “sudoers”, è possibile farlo con un semplice comando:
[guest@WEB-MGR (ttyp0) ~]$ sudo su -
[guest@WEB-MGR (ttyp0) ~]$
Il comando sudo su - ci riporta immediatamente alla console originale. Accesso negato.
Esistono altri utenti da tentare? Elencando le cartelle presenti all’interno di /home/ possiamo intuire chi ha accesso al sistema.
[guest@WEB-MGR (ttyp0) ~]$ ls /home/
ftp/ guest/ hide/ ho/ mw/ wm/ www-data/
Tra le varie cartelle, hide attira subito l’attenzione: il nome fa pensare a un’utenza di servizio “nascosta” creata dagli sviluppatori. Proviamo ad autenticarci riutilizzando la stessa password di guest.
WEB-MGR login: hide
Password: *****
[hide@WEB-MGR (ttyp0) ~]$ sudo su -
[root@WEB-MGR (ttyp0) ~]#
Root ottenuto! Come in ogni film di hacking che si rispetti, siamo entrati dalla backdoor.
Dov’è il server web?
Ora che possediamo accesso al sistema con root, possiamo leggere e modificare qualsiasi cosa. Per prima cosa, controlliamo se il server è in esecuzione. Usando il comando ps aux otteniamo un elenco dei processi, tra cui però non appare alcun server http.
Prima di continuare dobbiamo capire quale server stiamo cercando. Potrebbe essere nginx, apache2, lighttpd, o magari qualche server embedded base come uhttpd.
Fortunatamente nella cartella /etc/ è presente un file lighttpd.conf, che ci guida direttamente verso il server scelto dagli sviluppatori.
Provando a eseguire lighttpd, veniamo immediatamente fermati da un errore:
[hide@WEB-MGR (ttyp0) ~]$ lighttpd
lighttpd: error while loading shared libraries: libz.so.1: cannot open shared object file: No such file or directory
libz è una libreria esterna, solitamente inclusa nel sistema operativo base, che si occupa di comprimere e decomprimere file. Buona parte dei server web moderni ne ha bisogno per poter implementare la compressione HTTP, essendo le pagine HTML molto propense alla compressione.
All’avvio di lighttpd, uno speciale programma chiamato “linker dinamico” cerca e carica in memoria tutte le librerie di cui il software avrà bisogno. Le librerie di sistema, tra cui libz.so.1, si trovano solitamente all’interno della cartella /lib/, ma il linker effettua una ricerca anche in altre cartelle nel caso sia necessario.
Il fatto che lighttpd ci dica “No such file or directory” indica che la libreria potrebbe essere stata cancellata o corrotta a tal punto da diventare illeggibile.
Save slot 1
Fino ad ora ci siamo limitati a guardare ma non toccare, evitando di causare errori aggiuntivi su una memoria che sappiamo già essere danneggiata.
Per poter lavorare liberamente senza il rischio di distruggere l’unica copia dei dati rimasta, è utile creare una copia di backup del sistema operativo d’origine.
Fortunatamente, avendo già l’accesso root possiamo usare una combinazione di dd e netcat per inviare l’intero contenuto della scheda SD ad un computer a nostra scelta1. Spostando l’immagine su un computer esterno otteniamo anche la possibilità di utilizzare software molto più moderni e potenti, velocizzando il lavoro.
Dov’è finita la libreria?
Ora che siamo al sicuro, possiamo indagare su che fine abbia fatto libz.so.1.
Un controllo veloce rivela che il file “libz.so.1” esiste, ed è un collegamento al file “libz.so.1.2.3.3”.
Aggiungendo LD_DEBUG=libs prima di un comando, possiamo chiedere al linker di descrivere ogni operazione che compie.
[root@WEB-MGR (ttyp0) ~]## LD_DEBUG=libs lighttpd
[...]
2999: find library=libz.so.1 [0]; searching
2999: search cache=/etc/ld.so.cache
2999: search path=/lib:/usr/lib/tls/v5l/fast-mult:/usr/lib/tls/v5l:/usr/lib/tls/fast-mult:/usr/lib/tls:/usr/lib/v5l/fast-mult:/usr/lib/v5l:/usr/lib/fast-mult:/usr/lib:/lib/arm-linux-gnueabi/tls/v5l/fast-mult:/lib/arm-linux-gnueabi/tls/v5l:/lib/arm-linux-gnueabi/tls/fast-mult:/lib/arm-linux-gnueabi/tls:/lib/arm-linux-gnueabi/v5l/fast-mult:/lib/arm-linux-gnueabi/v5l:/lib/arm-linux-gnueabi/fast-mult:/lib/arm-linux-gnueabi:/usr/lib/arm-linux-gnueabi/tls/v5l/fast-mult:/usr/lib/arm-linux-gnueabi/tls/v5l:/usr/lib/arm-linux-gnueabi/tls/fast-mult:/usr/lib/arm-linux-gnueabi/tls:/usr/lib/arm-linux-gnueabi/v5l/fast-mult:/usr/lib/arm-linux-gnueabi/v5l:/usr/lib/arm-linux-gnueabi/fast-mult:/usr/lib/arm-linux-gnueabi (system search path)
2999: trying file=/lib/libz.so.1
2999: trying file=/usr/lib/tls/v5l/fast-mult/libz.so.1
2999: trying file=/usr/lib/tls/v5l/libz.so.1
2999: trying file=/usr/lib/tls/fast-mult/libz.so.1
2999: trying file=/usr/lib/tls/libz.so.1
2999: trying file=/usr/lib/v5l/fast-mult/libz.so.1
2999: trying file=/usr/lib/v5l/libz.so.1
2999: trying file=/usr/lib/fast-mult/libz.so.1
[... a bunch of other tries here ...]
lighttpd: error while loading shared libraries: libz.so.1: cannot open shared object file: No such file or directory
Il linker cerca in /lib/, ma poi tenta tutte le altre cartelle che conosce. libz.so.1 esiste ed è in /lib/. Come mai sta venendo ignorato?
È possibile che qualcosa abbia sostituito libz.so.1 con un file completamente diverso? Per curiosità, ho provato a usare lo strumento file, che analizza i file e ne descrive il contenuto:
/lib$ file libz.so.1.2.3.3
libz.so.1.2.3.3: ELF 32-bit LSB shared object, *unknown arch 0x20* version 1 (SYSV)
can't read elf program headers at 1073741876, missing section headers at 1130896
Ignorando “unknown arch”, l’errore “can’t read elf program headers” rivela il mistero: il file è completamente corrotto.
In cerca di un libz.so.1.2.3.3
Nonostante libz sia inclusa in qualsiasi computer con Linux (e probabilmente anche Windows), non possiamo prendere un file libz qualsiasi e sostituirlo nella cartella di sistema. Man mano che le librerie evolvono, infatti, cambiano il loro funzionamento e le versioni successive diventano incompatibili con quelle precedenti.
In più, questo non è un computer normale, ma è basato su una CPU “ARM”: anche se la libreria fosse corretta, la CPU non saprebbe come interpretarla.
Fortunatamente libz è così diffusa che possiamo dare per scontato che sia inclusa nell’immagine di sistema creata dal produttore. Per ottenere quell’esatta versione, dobbiamo capire quando questa libreria è stata creata e trovare un’immagine di quell’epoca.
## ls -lah libz.so.1*
-rw-r--r-- 1 root root 81K 17 nov 2010 libz.so.1.2.3.3
La libreria è stata creata il 17 novembre 2010, esattamente il giorno precedente al rilascio di questa immagine ISO: https://download.atmark-techno.com/armadillo-440/iso/a400_20101118_free.iso
Scaricando l’ISO ed estraendola, otteniamo l’intero contenuto originale della cartella /lib/.
Per precauzione ho confrontato tutte le librerie originali con quelle presenti nella scheda: corrispondevano tutte, tranne libz, che ho sostituito immediatamente.
Secondo tentativo
Ora che la libreria è stata sostituita, possiamo riprovare ad eseguire lighttpd:
[root@WEB-MGR (ttyp0) /bin]## lighttpd
2026-04-08 17:44:12: (../../src/server.c.521) No configuration available. Try using -f option.
L’errore è cambiato: ciò significa che libz è stata finalmente caricata! lighttpd ci sta semplicemente dicendo che non trova un file di configurazione. Proviamo ad fornirgli il file lighttpd.conf trovato prima (e l’opzione -D, in modo che lighttpd non vada in background):
[root@WEB-MGR (ttyp0) ~]## lighttpd -D -f /etc/lighttpd.conf
../../src/configfile.c.792: 0, (null)
Per quanto questo errore possa sembrare criptico, una veloce ricerca indica che si tratta di un problema di sintassi del file di configurazione. Vediamo cosa c’è all’interno:
## lighttpd configuration file
#
## use it as a base for lighttpd 1.0.0 and above
#
## $Id: lighttpd.conf,v 1.7 2004/11/03 22:26:05 weigon Exp $
############ Options you really have to take care of ####################
## [���Ѥ���module������] modules to load
[... normal config file ...]
fastcgi.server = (
0".app" => (
! "localhost" => (
" 0 "socket" =>
"/tmp/app-Socket.socket"(
"max-procs" => 1,
"bin-path" => 2/mspec/srg/�pp.rb",
## ! ( 0 "bi�/environment" 5> ("TZ* =. "JST-9")
$) ` �),
( � $ ".html" => (
"localhost => (� � � "socket" =>
0 $ "/tmp/app/socket2.socket",
` "max-procs" => 1,
!"bin-path" => "/chamb/src/route.rb",
!` " )
� )
## $ ".rb" => (
## "localhost" => (## ( " "/tmp/ruby-socket.socket",
## "max-procs" =>"1,
## $ "Bin-path" => "/usr/bin/ruby"
## " ( ( )
## )
)
Ecco l’esempio perfetto di bitrot! All’interno del file di configurazione, alcuni bit hanno cambiato stato e in base alla loro posizione hanno causato:
- caratteri inesistenti o non validi, ora mostrati come “�”
- sostituzioni di caratteri con altri: il carattere
\n(a capo) prima di"localhost"è diventato uno spazio, unendo due righe - cambi tra maiuscole e minuscole:
bin-pathè diventatoBin-path
Ed è questo il motivo per cui il bit-rot è così pericoloso: mentre la perdita totale di un file rende il problema immediatamente evidente, il bitrot altera in modo subdolo e graduale i file, fino a quando il sistema diventa troppo degradato per continuare a funzionare. Il pericolo sta nell’ambiguità di non sapere quali file sono intatti, e quali hanno subito variazioni.
In questo caso il bitrot aveva colpito l’inizio e la fine del file, mentre la parte centrale era completamente intatta.
Riscrivere sulle spalle di chi è stato addestrato a riscrivere
La mia conoscenza di lighttpd in combinazione con ruby non è abbastanza approfondita da poter riscrivere il file da capo: di conseguenza ho preso spunto da un metodo utilizzato per addestrare i primi LLM.
BERT (creato da Google nel 2018) è un modello del linguaggio addestrato utilizzato il metodo “MLM” (Masked Language Modeling). Il concetto è semplice: si offre al modello un testo e si sostituiscono alcune parole con il token [mask]. L’obbiettivo del modello è quello di sostituire la maschera con le parole mancanti e ottenere il testo originale.
I modelli neurali moderni, con miliardi di parametri, sono in grado di eseguire questo compito molto bene. Ho sostituito tutti i caratteri corrotti, o che a occhio sembravano invalidi, con il carattere ?, e poi ho utilizzato ollama con un modello locale e il seguente prompt per ricostruire il file.
This attachment is a config file of an old lighttpd server recovered from a corrupted sd card.
The bit rot caused bit flips that modified characters through the entire file.
Non-printable characters were replaced with question marks (?): those are supposed to be corrected.
Be aware of bit flips that cause subtle syntax errors such as missing semicolons, case folding and letter replacements.
Provide a corrected file. Do not rewrite it, reorder options or optimize. Only edit the corrupted parts.
Nonostante il prompt, purtroppo i modelli moderni tendono troppo voler “aiutare” e spesso riscrivono da capo, ottimizzano o rielaborano l’input piuttosto che modificarlo e basta.
Quindi, invece di fidarmi ciecamente dell’output del modello, ho verificato e applicato manualmente le differenze riga per riga, integrando solo le correzioni effettive e ignorando i commenti extra aggiunti dall’LLM.
Nonostante il file di configurazione ora valido e il server in esecuzione, l’interfaccia web era raggiungibile ma mostrava una pagina bianca. Controllando il file di log, è emerso un problema in un file ruby responsabile dell’interfaccia.
Siccome il disco era ormai confermato corrotto e non sapevo con certezza se ci fossero altri file danneggiati, ho deciso di controllarli tutti.
Un file ruby afflitto da bitrot, statisticamente, avrà almeno un carattere non ASCII (�). Quando il comando file analizza un file con caratteri non ASCII lo classifica come “binary data”. Possiamo quindi cercare tutti i file ruby classificati in questo modo per ottenere una lista di quelli corrotti.
## Feed all the *.rb files to the "file" command, then only include lines that match binary data
$ find . -name '*.rb' -exec file {} \; | grep 'binary data'
./RqstHndl.rb: a /usr/bin/ruby -I/chamb/src -Ku script executable (binary data)
Solo RqstHndl.rb è risultato corrotto, ed è stato riparato utilizzando lo stesso metodo adottato per la configurazione sopra.
Successo!
Aprendo l’interfaccia da un browser, è apparsa finalmente l’interfaccia descritta nel manuale:
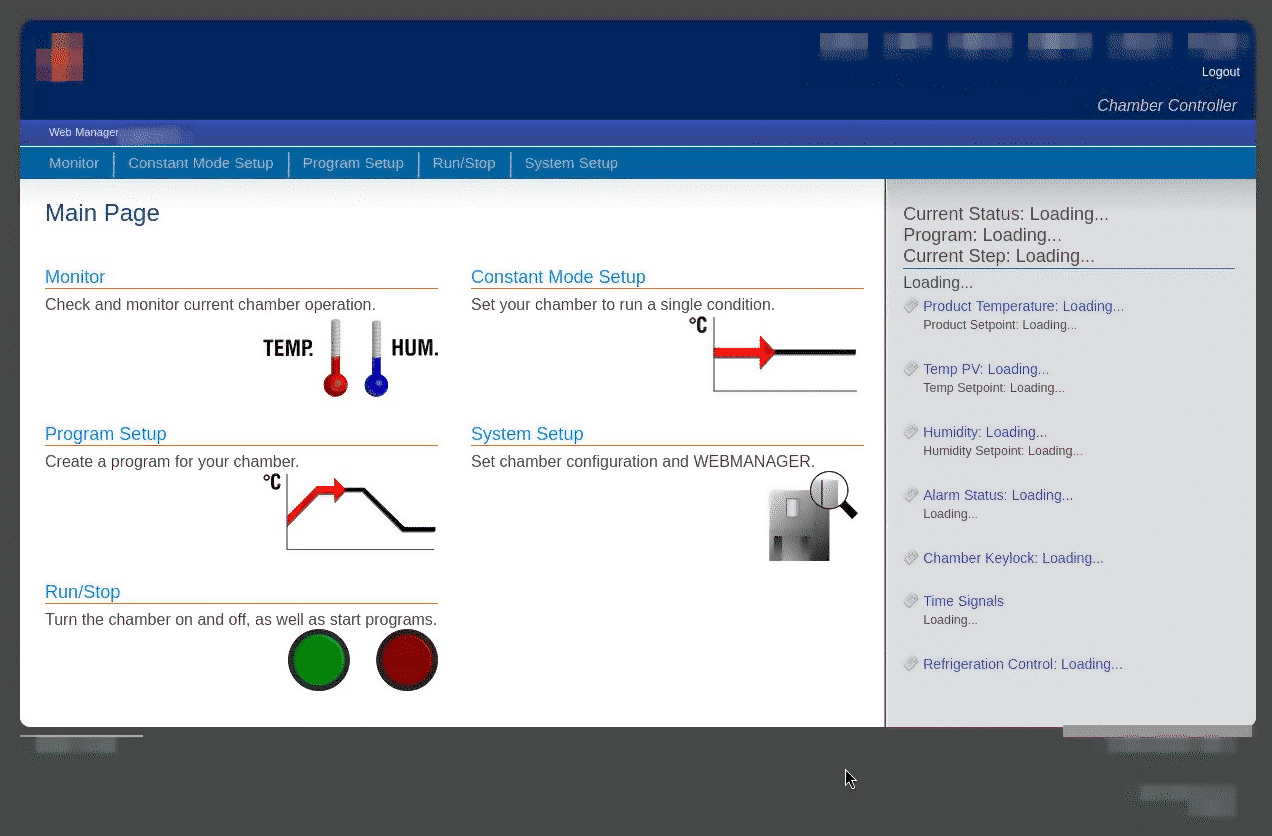
Sostituzione della SD
L’interfaccia è visibile e funzionante. La scheda SD su cui stava girando, però, aveva già mostrato segni di instabilità. È necessario quindi sostituirla con una nuova e, possibilmente, più longeva.
Aprire l’involucro del modulo è facile: all’interno si trova solo un SBC con una scheda aggiuntiva che mantiene data e ora (RTC) e un’interfaccia RS485 supplementare utilizzata per la connessione al PLC del macchinario.

Il filesystem interno è di soli 2 GB, ma l’uso di una scheda classificata come “High Endurance”, unito alla scelta di una capienza superiore (16GB) per distribuire le scritture su un area più ampia, renderà ancora più improbabile che il difetto accada in futuro (o almeno, entro la dismissione del macchinario).
È stato tentato un nuovo avvio per verificare la compatibilità con la nuova scheda, questa volta osservando tramite porta seriale la presenza di errori aggiuntivi. Non tutto è andato per il meglio:
[... bootloader and kernel boot above ...]
Running local start scripts.
Starting udevd: udevd[164]: add_to_rules: unknown key 'KERN�L' in /etc/udev/rules.d/z99_usb_image_update.rules:1
udevd[164]: add_to_rules: unknown key 'B�S' in /etc/udev/rules.d/z99_usb_image_update.rules:1
udevd[164]: add_to_rules: unknown key 'KERNML' in /etc/udev/rules.d/z99_usb_image_update.rules:2
udevd[164]: add_to_rules: invalid rule '/etc/udev/rules.d/z99_usb_image_update.rules:2'
done
Loading /etc/config: done
Changing file permissions: udevd-event[227]: run_program: exec of program '/bi�/sh' failed
udevd-event[229]: run_program: exec of program '/bi�/sh' failed
[... infinite loop of run_program ...]
Questi errori ci hanno permesso di individuare altri file da correggere in /etc/profile e /etc/udev/rules.d/. Inoltre, gli errori generavano un loop infinito di scritture nel log di sistema, sommergendo la SD di scritture.
È possibile che questo piccolo errore nella regola udev abbia causato tutti gli altri problemi.
Controllo del filesystem
Prima di dichiarare il sistema sicuro è necessario utilizzare fsck.ext3 sulla partizione per trovare e correggere gli errori rimanenti. Solitamente, fsck corregge gli errori del filesystem e sposta i file orfani o irrecuperabili nella cartella lost+found/.
$ sudo fsck.ext3 -v -y /dev/sdb1
e2fsck 1.47.3 (8-Jul-2025)
/dev/sdb1 contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Directory entry for '.' in ... (64209) is big.
Split? yes
Directory inode 64209, block #0, offset 12: directory corrupted
Salvage? yes
Pass 3: Checking directory connectivity
'..' in /etc/config.bak (64209) is <The NULL inode> (0), should be /etc (64001).
Fix? yes
Couldn't fix parent of inode 64209: Couldn't find parent directory entry
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: ***** FILE SYSTEM WAS MODIFIED *****
/dev/sdb1: ********** WARNING: Filesystem still has errors **********
4583 inodes used (3.82%, out of 120000)
39 non-contiguous files (0.9%)
1 non-contiguous directory (0.0%)
## of inodes with ind/dind/tind blocks: 146/1/0
37720 blocks used (7.86%, out of 479990)
0 bad blocks
1 large file
3687 regular files
268 directories
132 character device files
133 block device files
0 fifos
4294967295 links
353 symbolic links (353 fast symbolic links)
1 socket
------------
4573 files
C’è ancora un problema. Ironicamente, è proprio il backup dei file di configurazione a impedire a fsck di riparare il filesystem.
Per capire cosa sta succedendo, dobbiamo fare un passo indietro e spiegare cos’è un inode.
Nei filesystem come ext3, il nome associato al file è solo un etichetta comoda che viene data dall’utente per individuarlo.
I dati reali e i metadati del file (permessi, dimensione, dove si trovano i blocchi fisici sul disco) sono memorizzati in una struttura dati chiamata inode, a cui sono assegnati numeri univoci.
Quando il sistema cerca /etc/config.bak, in realtà va a cercare l’inode associato a quel nome, 64209.
Guardando il report finale di fsck, un valore bizzarro salta all’occhio: il filesystem riporta 4.294.967.295 collegamenti (hard link). Siccome ogni collegamento è, a sua volta, associato a un inode, è tecnicamente impossibile avere più collegamenti che inodes.
In più, il numero corrisponde esattamente a 0xFFFFFFFF, ovvero il più grande numero intero rappresentabile a 32 bit - una coincidenza troppo strana per essere casuale.
Questo valore fuori scala è causato dall’inode 64209, che il sistema associa proprio alla cartella /etc/config.bak, la stessa che sta bloccando fsck.
Purtroppo, tentare di eliminare quella cartella usando il normale comando rmdir causa un crash immediato del sistema. Per risolvere la situazione serve agire a basso livello: dovremo usare debugfs, uno strumento che consente di modificare “chirurgicamente” il filesystem, agendo direttamente sugli inode.
## debugfs -w /dev/sdb1
debugfs 1.47.3 (8-Jul-2025)
debugfs: stat <64209>
Inode: 64209 Type: directory Mode: 0775 Flags: 0x0
Generation: 3813769555 Version: 0x00000000:00000000
User: 0 Group: 0 Project: 0 Size: 4096
File ACL: 0
Links: 2 Blockcount: 8
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x4e264393:00000000 -- Wed Jul 20 04:55:15 2011
atime: 0x69d67a22:60bfcb28 -- Wed Apr 8 17:54:10 2026
mtime: 0x4e264393:00000000 -- Wed Jul 20 04:55:15 2011
crtime: 0x00000000:00000000 -- Thu Jan 1 01:00:00 1970
Size of extra inode fields: 32
BLOCKS:
(0):268290
TOTAL: 1
debugfs:
Lo strumento mette a disposizione una shell interattiva. Scrivendo ncheck 64209 verifichiamo a quale percorso corrisponde l’inode corrotto:
debugfs: ncheck 64209
Inode Pathname
64209 /etc/config.bak
Come sospettato, è il backup. Siccome si tratta di una cartella vuota, possiamo rimuoverla direttamente agendo sul filesystem:
debugfs: rmdir /etc/config.bak
debugfs: quit
Siamo pronti per eseguire nuovamente il controllo. Nel caso la rimozione della cartella abbia causato altre inconsistenze nel filesystem, fsck potrà occuparsene e terminare la riparazione, ottenendo un filesystem pulito al 100%.
## fsck.ext2 /dev/sdb1
e2fsck 1.47.3 (8-Jul-2025)
/dev/sdb1 contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: 4582/120000 files (0.9% non-contiguous), 37719/479990 blocks
Il sistema è stato completamente ripristinato. Per sicurezza, è stata creata un’immagine disco del risultato finale per poter ripristinare il tutto in caso di problemi futuri.
Conclusioni
Quando si progetta un dispositivo embedded, specialmente se dovrà funzionare senza supervisione per decenni, una corretta attenzione all’integrità del filesystem è cruciale. I bit flip accadranno prima o poi e il sistema deve essere in grado di ripararli o, perlomeno, rilevarli.
Ci sono alcuni accorgimenti da seguire:
- Mantenere il sistema in sola lettura: separare i dati utente e di sistema in partizioni diverse e permettere la scrittura solo sulla partizione utente.
- Considerare la possibilità di corruzione totale: avere una partizione extra per un’immagine “factory” o “recovery” che possa riportare il dispositivo allo stato di fabbrica.
- Se possibile, eseguire tutto dalla memoria: anche se la RAM embedded raramente è ECC, qualsiasi problema potrà essere risolto con un riavvio.
- Scrivere in modo atomico e validare le scritture (CoW): invece di sovrascrivere direttamente i file di configurazione, scriverli altrove e poi spostarli nella destinazione.
- Loggare solo l’essenziale e in blocchi: non è necessario scrivere continuamente su SD. Quando si porta il dispositivo in produzione, ridurre la frequenza dei commit così che le scritture siano deframmentate oppure disattivare completamente i log.
- Utilizzare filesystem moderni con funzioni di “checksum” e “scrub”, che controllano e riscrivono i dati corrotti prima che vengano persi del tutto.
Tutto questo può essere facilmente implementato con progetti Open Source come Yocto Linux, Alpine Linux o progetti della community come DietPi.
-
Idealmente si dovrebbe creare un immagine disco a sistema spento, dato che farlo su un sistema in esecuzione produce al 100% un immagine inconsistente. Non è un grosso problema qui poiché il filesystem è comunque corrotto e i file di cui abbiamo bisogno non vengono mai modificati. ↩