3 milioni di richieste al giorno, zero CDN: l'ottimizzazione di CoMaps
CoMaps è un’applicazione di navigazione Open Source che utilizza i dati di OpenStreetMap come base cartografica. Uno dei suoi punti di forza è la capacità di funzionare completamente offline, scaricando le mappe in anticipo o a mano a mano che si esplora.
L’app fornisce pacchetti compressi e distillati dai dati di OpenStreetMap, che includono solo le informazioni utili a una navigazione di tutti i giorni. In questo modo con pochi GB è possibile ottenere mappe sempre disponibili e una ricerca completamente offline.
Non è dato sapere quanti siano gli utenti effettivi1 (in quanto non ci sono nè tracking nè statistiche), tuttavia fornire mappe di alta qualità su una scala così grossa e soprattutto mantenendo la privacy degli utenti è una sfida infrastrutturale interessante.
Lo scopo di CoMaps è quello di abbandonare CDN commerciali e utilizzare per una serie di nodi indipendenti gestiti direttamente dai volontari del progetto. In questo modo, il traffico passerebbe esclusivamente attraverso soggetti realmente coinvolti e allineati con gli obbiettivi del progetto, senza intermediari.
Da Aprile 2026 unfoxo offre a CoMaps il nodo “comaps-it1”.
È realmente una CDN?
L’obbiettivo di una CDN è quello di portare i dati il più vicino possibile all’utente: i dati vengono copiati e distribuiti su diversi nodi che coprono maggior numero possibile di aree geografiche differenti. In questo modo, in qualsiasi luogo si trovi l’utente, statisticamente avrà almeno un nodo abbastanza vicino da cui scaricare i dati nel modo più veloce possibile. Nodi più vicini significano anche costi del traffico inferiore e maggiore resilienza.
Lo scopo della “CDN” di CoMaps è diverso: ogni client si connette a nodi casuali e scarica solo le regioni della mappa in formato compresso. In questo modo diventa quasi impossibile capire, correlando le richieste di un utente in particolare, la sua posizione esatta.
In più, essendo gli stati divisi in sezioni molto grossolane e non in “tiles” (i “quadretti” classici delle altre app di navigazione), nel caso peggiore è possibile conoscere solo una posizione molto approssimata dell’utente.
L’architettura del nodo comaps-it1
In una CDN il server http è ciò che si contrappone tra utente e dati: è quindi necessario che sia efficiente e ottimizzato.
- Filesystem: Bcachefs su SSD SATA, con caching nvme
- Sistema operativo: Alpine Linux
- Web Server: Nginx
Per la sincronizzazione il team di CoMaps utilizza sftp, che è stato installato su un container separato con permessi di scrittura solo nella cartella che verrà poi servita dal nodo.
Bcachefs è stato scelto per la possibilità di poter creare un archivio a due “strati”: davanti, i dischi nvme eccellono in velocità e ricevono tutte le scritture e le letture dei dati più “caldi”.
I dischi SATA, al contrario, vengono utilizzati come archivio per i dati utilizzati meno, fornendo lo spazio necessario ma a un costo molto inferiore e con una longevità maggiore.
Alpine Linux è stato scelto per la leggerezza e la semplicità: si tratta del sistema operativo su cui si basano moltissime immagini di Docker, ma eccelle anche utilizzato come sistema operativo base e si avvicina molto bene al metodo “old school” di gestione di server.
Il server web non è un elemento critico: siccome la banda è il limite per questo progetto, qualsiasi server web probabilmente l’avrebbe saturata. In questo caso ho deciso di usare nginx per la familiarità e la possibilità di agire sia come server statico che come proxy.
Ottimizzazione delle performance
Il server è stato avviato con le impostazioni di default per un periodo iniziale e il logging attivo, in modo da poter stabilire una baseline. Il server, sostenuto dalla pool SSD, era in ogni caso in grado di saturare la WAN attraverso il quale era collegato.
Sono sorte però opportunità per ottimizzare ancora di più il sistema: un carico minore significa meno consumo di energia, una durata più lunga dei componenti ma anche la possibilità di dirigere quel carico verso altri compiti più importanti.
La legge di pareto
Chiunque abbia avuto a che fare con grandi numeri conoscerà sicuramente la legge di Pareto. Statisticamente, il 20% delle cause genera l‘80% degli effetti.
Ciò significa che, se riusciamo a individuare e ottimizzare “il 20%” responsabile del lavoro, potremo teoricamente ottenere l‘80% di performance in più.
Ho quindi raccolto un giorno di log. In totale sul server sono passate all’incirca 3 milioni di richieste.
Utilizzando uno script bash, possiamo estrarre facilmente solo le richieste relativamente alle mappe dividerle per stato:
## sed -n 's/.*\/260405\/\([^_.]*\).*/\1/p' access.log | sort | uniq -c | sort -nr | awk '{cnt[NR]=$1; name[NR]=$2; total+=$1; lines=NR} END {for(i=1;i<=lines;i++)
printf "%8d %6.2f%% %s\n", cnt[i], (cnt[i]/total)*100, name[i]}'
934949 32.25% France
532499 18.37% Germany
252621 8.71% US
148178 5.11% Italy
98293 3.39% Netherlands
86948 3.00% Spain
61763 2.13% Belgium
57862 2.00% Austria
53080 1.83% Switzerland
51552 1.78% World
50985 1.76% Canada
49935 1.72% UK
[... altri stati qui ...]
Dai log emerge chiaramente: l‘80% del traffico è generato da soli 12 stati su 220. Nel nostro caso il 5% causa l‘80% del traffico. Possiamo quindi concentrarci nell’ottimizzare questa piccola parte per ottenere un risultato nettamente migliore.
La ram non usata è ram sprecata
Sin da subito è emersa un’inefficienza del sistema: la maggior parte delle richieste leggeva direttamente dal disco. Un operazione comunque efficiente grazie all’utilizzo degli SSD ma che, in caso di altri carichi concorrenti, avrebbe sicuramente causato rallentamenti.
La causa era semplice: Linux utilizza pesantemente la ram libera come cache del disco, e il container dedicato al server web aveva solo 512MB allocati. Poichè buona parte della memoria era occupata dal sistema stesso, il server era costretto a “buttare via” i dati appena letti senza poterli tenere in memoria.
Dando invece a Linux la giusta quantità di RAM, possiamo fare in modo che la sfrutti al meglio riempiendola con i dati più “caldi” provenienti dal disco.
Questa “pienezza” è in realtà solo apparente, ed infatti la memoria usata per il caching può essere liberata immediatamente nel caso un altro software ne abbia bisogno. Non tutti ne sono a conoscenza e addirittura esiste un sito web dedicato che spiega bene il concetto.
A quanto corrisponde il 5% individuato prima? Possiamo scoprirlo sommando la dimensione di tutti gli stati che lo compongono:
## du -ch France_* Germany_* US_* Italy_* Netherlands_* Spain_* Belgium_* Austria_* Switzerland_* World* Canada_* UK_*
[...]
38.7G total
Ho quindi allocato al server web circa 40GB di RAM, in modo da dare l’opportunità al sistema di tenere in memoria buona parte di quei file. Nel giro di qualche ora il sistema riportava di averne usati 39.3G (colonna buff/cache).
## free -h
total used free shared buff/cache available
Mem: 125.7G 39.4G 3.0G 1.9G 39.3G 40.3G
Ciò ha causato un immediata discesa dell’utilizzo del disco, che da un utilizzo medio di 15MB/s con picchi di 60MB/s si è stabilizzato a circa 5MB/s con picchi di 10MB/s (praticamente un terzo), con una curva sempre più bassa a mano a mano che l’algoritmo ottimizzava i file più letti.
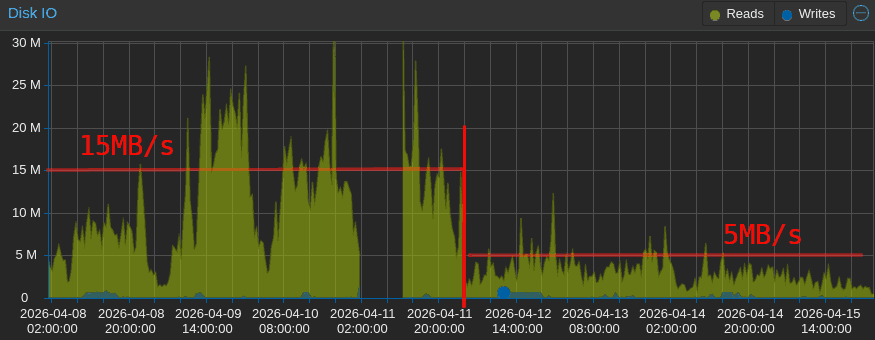
L’effetto benefico della RAM aggiuntiva appare ancora più evidente dal grafico della pressione IO, che indica la percentuale di tempo “persa” ad aspettare che i dischi siano disponibili.
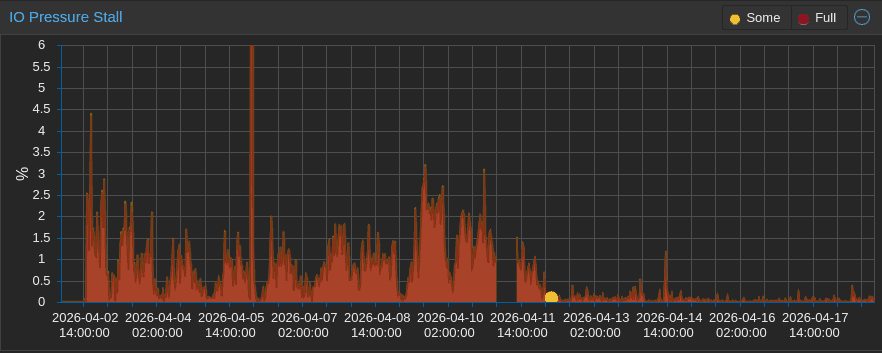
Chi ha bisogno di atime?
Risolto il nodo delle letture frequenti, rimane un altro fatto di cui tener conto: le scritture frequenti.
Anche se leggendo un file questo non viene effettivamente “modificato”, tra i propri metadati contiene l’ultima volta che ha subito un accesso.
Questo dato viene aggiornato dal sistema operativo ed è visualizzabile con il comando stat:
## stat World.mwm
File: World.mwm
Size: 53104836 Blocks: 103728 IO Block: 4096 regular file
Device: 800h/2048d Inode: 5518608 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ UNKNOWN) Gid: ( 1000/ UNKNOWN)
Access: 2026-04-18 10:28:45.836942564 +0000
Modify: 2026-04-06 07:03:48.000000000 +0000
Change: 2026-04-07 07:01:31.892520553 +0000
Ciò significa che ad ogni file scaricato, anche nel caso il file sia presente in RAM, corrisponde una piccola scrittura che aggiorna quel valore. È utile in caso di audit o per tenere un elenco di file recenti, ma nel nostro caso siccome ogni file ha accessi continui, perde completamente di significato.
Non si tratta di molto traffico, ma è comunque possibile disattivarlo aggiungendo le opzioni di mount noatime o lazyatime.
Le due opzioni devono essere messe nel file /etc/fstab e causano i seguenti effetti:
noatime: la data di accesso non viene mai aggiornatalazyatime: la data di accesso viene aggiornata solo in concomitanza con una modifica (che avrebbe comunque causato una scrittura) o passate 24 ore dall’ultimo aggiornamento
Nel mio caso ho abilitato globalmente lazyatime sull’intero filesystem: controllare il tempo di accesso può essere comodo per capire se alcuni file sono utilizzati o no, e i log di accesso permettono comunque di tirare fuori i timestamp esatti nel caso sia necessario.
Quelle continue scritture
Non ci avevo mai fatto caso, ma la totalità di traffico in scrittura del server web era causata dal file access.log, aggiornato ad ogni visita. Ogni richiesta generava una riga, e ogni riga generava una scrittura sul file.
Nginx fornisce tre opzioni aggiuntive da aggiungere alle impostazioni di logging:
access_log /var/log/nginx/access.log privacyfmt gzip buffer=32k flush=10m;
Ecco l’effetto che ha ognuno di queste:
gzip: L’intero log viene compresso al volo con gzip (livello 1). Nel mio caso,758MBdi log diventano34.4MB(22 volte meno)buffer=32k: Verrà scritto su disco solo al raggiungimento di 32kb di log in sospeso…flush=10m: … o finchè non sono passati 10 minuti dall’ultima scrittura
L’unico svantaggio di questo approccio è la possibilità di perdere fino a 10 minuti di log in caso di crash del server. Non ho interesse nel tenere log così granulari, di conseguenza ho applicato queste direttive globalmente.
Nota: al termine ho comunque disattivato i log per policy CoMaps. Il logging iniziale è stato effettuato con un formato che non includeva indirizzi IP e User-Agent (privacyfmt).
Conclusioni
Rendere disponibile il nodo per CoMaps non è solo un modo per contribuire a un progetto Open Source, ma anche l’opportunità di imparare a conoscere le sfide causate da un traffico particolare come quello causato da questa app.
Nonostante il traffico significativo, la presenza di altri nodi contribuisce a distribuire efficacemente il traffico ben sotto la soglia di saturazione. I client sono progettati per scaricare da quanti più nodi possibile in contemporanea e ritentare in caso di errore.
Anche se ci fosse, in futuro, la necessità di limitare il traffico, i client si adatterebbero di conseguenza scaricando da altri nodi più veloci.
Sono felice di fornire questo nodo e vi invito a contribuire anche solo scaricando l’app per provarla e lasciare un’opinione. CoMaps è un progetto relativamente nuovo e serve molto aiuto in tutti i fronti!
-
Google dice “100K+” download, ma probabilmente ci sono molti più download da F-Droid e altri store alternativi. ↩